用多线程并发的方式来计算两个矩阵的乘法_、试用线程的方法编写两个10*10矩阵的相乘的计算程序,用10个线程完成结果矩j-程序员宅基地
技术标签: 程序
要求很简单,计算两个矩阵的乘法。为了加速,这里面使用了pthread库,来并发计算。
基本思路如下图。
比如用两个线程来计算。矩阵A * B。那么就把A分成两份。比如下图,就是0,2,4和1,3,5这两份。
在线程1中计算第0,2,4行和B个列的乘积,在线程2中计算1,3,5行和B各个列的乘积。
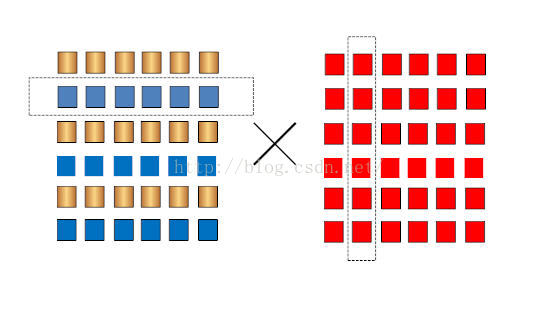
思路很简单。最后代码如下:
// pthread.cpp : Defines the entry point for the console application.
//
#include <stdlib.h>
#include "pthread.h"
#include <x86intrin.h>
#include <xmmintrin.h>
int THREADS_COUNT = 4;
pthread_t threads[16];
int PRINT = 0;
void test(int dim);
int * multiplyPthread(int * a, int* b, int dim);
int * multiplySimple(int * a, int* b, int dim);
int mul(int* a, int* b, int row, int col, int dim);
struct THREAD_PARAM {
int * a;
int * b;
int * buffer;
int dim;
int index;
int step;
};
struct THREAD_PARAM params[16];
void output(int * buf, int dim) {
for (int i=0; i<dim; i++) {
for (int j=0; j<dim; j++) {
printf("%d ", buf[i * dim + j]);
}
printf("\n");
}
printf("============\n");
}
int main(int argc, char* argv[])
{
int size[] = {4, 16, 32, 48, 64, 128, 256, 512, 1024, 2048, 4096};
for (int i=0; i<8; i++) {
test(size[i]);
}
return 0;
}
void test(int dim) {
int * a = (int*)malloc(dim * dim * sizeof(int));
for (int i=0; i<dim; i++) {
for (int j=0; j<dim; j++) {
a[i * dim + j] = i * j + 1;
}
}
int * b = (int*)malloc(dim * dim * sizeof(int));
for (int i=0; i<dim; i++) {
for (int j=0; j<dim; j++) {
b[i * dim + j] = i * j + 2;
}
}
struct timeval start0,start1,start2;
struct timeval end0,end1,end2;
unsigned long diff0, diff1,diff2;
gettimeofday(&start0,NULL);
int * result = multiplySimple(a, b, dim);
gettimeofday(&end0,NULL);
gettimeofday(&start1,NULL);
int * resultPthread = multiplyPthread(a, b, dim);
gettimeofday(&end1,NULL);
// gettimeofday(&start2,NULL);
// int * resultPthreadSSE = multiplyPthread(a, b, dim, 1);
// gettimeofday(&end2,NULL);
if (PRINT) {
output(a, dim);
output(b, dim);
output(result, dim);
output(resultPthread, dim);
// output(resultPthreadSSE, dim);
}
diff0 = 1000000 * (end0.tv_sec-start0.tv_sec)+ end0.tv_usec-start0.tv_usec;
diff1 = 1000000 * (end1.tv_sec-start1.tv_sec)+ end1.tv_usec-start1.tv_usec;
//diff2 = 1000000 * (end2.tv_sec-start2.tv_sec)+ end2.tv_usec-start2.tv_usec;
printf("(%d) the difference for simple is %ld\n", dim, diff0);
printf("(%d) the difference for threaded is %ld\n", dim, diff1);
//printf("(%d) the difference for threaded with SSE is %ld\n", dim, diff2);
free(result);
free(resultPthread);
free(a);
free(b);
}
int * multiplySimple(int* a, int* b, int dim) {
int * result = (int*)malloc(dim * dim * sizeof(int));
int sum = 0;
for (int i=0; i<dim; i++) {
for (int j=0; j<dim; j++) {
sum = 0;
for (int k=0; k<dim; k++) {
sum += (a[dim * i +k] * b[dim * k + j]);
}
result[dim * i + j] = sum;
}
}
return result;
}
void *Calculate(void *param)
{
struct THREAD_PARAM *p = (struct THREAD_PARAM*)param;
int dim = p->dim;
int index = p->index;
int *a = p->a;
int *b = p->b;
int *result = p->buffer;
int step = p->step;
int sum = 0;
for (int i=index; i<dim; i+=step) {
for (int j=0; j<dim; j+=1) {
sum = 0;
// int sum = mul(a, b, i, j, dim);
for (int k=0; k<dim; k++) {
// printf("cal %d, %d, %d\n", i, j, k);
sum += (a[dim * i +k] * b[dim * k + j]);
}
result[dim * i + j] = sum;
}
}
pthread_exit(NULL);
return 0;
}
int * multiplyPthread(int* a, int* b, int dim) {
int * result = (int*)malloc(dim * dim * sizeof(int));
for (int i=0; i<THREADS_COUNT; i++) {
params[i].buffer = result;
params[i].index = i;
params[i].dim = dim;
params[i].step = THREADS_COUNT;
params[i].a = a;
params[i].b = b;
int rc = pthread_create(&threads[i], NULL, Calculate, (void *)(¶ms[i]));
}
for(int t=0; t<THREADS_COUNT; t++) {
void* status;
int rc = pthread_join(threads[t], &status);
if (rc) {
printf("ERROR; return code from pthread_join() is %d\n", rc);
}
// printf("Completed join with thread %d status= %ld\n",t, (long)status);
}
return result;
}
# clang -O1 -lpthread -Wall mul.c
运行环境:
CentOS7, 4核的CPU,所以这里开了4个线程。
运行结果分析。
当矩阵的大小比较小的时候,普通的矩阵乘法比多线程的算法快得多。这也是可以理解的,因为创建线程需要一定的时间。
当矩阵的大小为64时,多线程的时间和普通单线程的时间基本上相同。
当矩阵的大小大于64时,多线程的时间明显好于单线程。
当矩阵的大小大于256时,多线程的性能达到单线程的4倍左右,很理想:
(4) the difference for simple is 1
(4) the difference for threaded is 420
(16) the difference for simple is 10
(16) the difference for threaded is 117
(32) the difference for simple is 63
(32) the difference for threaded is 151
(48) the difference for simple is 177
(48) the difference for threaded is 196
(64) the difference for simple is 379
(64) the difference for threaded is 329
(128) the difference for simple is 4456
(128) the difference for threaded is 2376
(256) the difference for simple is 40366
(256) the difference for threaded is 10581
(512) the difference for simple is 387046
(512) the difference for threaded is 97153
智能推荐
php酷狗音乐API接口,酷狗音乐抓取api-程序员宅基地
文章浏览阅读1k次。关键词抓取歌曲列表,获取hashhttp://mobilecdn.kugou.com/api/v3/search/song?format=json&keyword=%E6%88%91%E4%BB%AC%E4%B8%8D%E4%B8%80%E6%A0%B7&page=1&pagesize=20&showtype=1{"status":1,"error":"","dat..._r=play/getdata
华为云云耀云服务器L实例评测|在Docker环境下部署Mysql数据库_华为云 httpd+mysql实例-程序员宅基地
文章浏览阅读659次,点赞3次,收藏3次。华为云云耀云服务器L实例评测|在Docker环境下部署Mysql数据库_华为云 httpd+mysql实例
python模型持久化_Python模型本地持久化存储-程序员宅基地
文章浏览阅读295次。Python模型本地持久化存储通常我们线下训练好的模型,部署到线上运行,这就需要把模型进行本地硬盘持久化,比如保持到文件中,然后再在其他主机上导入内存进行分类和预测。下面就介绍几种模型持久化存储方法。1. pickle模块pickle是python标准模块,一种标准的序列化对象的方法。你可以使用pickle操作来序列化你的任何类对象,当然也包括机器学习模型,保存这种序列化的格式到一个文件中。需要的..._pytorch 网络模型持久化存储
如何判断一段程序是由C++编译还是C编译-程序员宅基地
文章浏览阅读3.1k次,点赞3次,收藏12次。(1)如果是要你的代码在编译时就发现编译器类型,就判断_cplusplus或_STDC_宏,如果是一个C文件被编译,那么_STDC_就会被定义,_STDC_是预定义宏,当它被定义后,编译器将按照ANSIC标准来编译C语言程序。通常许多编译器还有其他编译标志宏。#ifdef __cpluspluscout<<"c++";#elsecout&l..._判断一段程序是由c
win7家庭版桌面没有计算机图标,win7系统桌面和控制面板里都没计算机图标的解决方法...-程序员宅基地
文章浏览阅读525次。很多小伙伴都遇到过win7系统桌面和控制面板里都没计算机图标的困惑吧,一些朋友看过网上零散的win7系统桌面和控制面板里都没计算机图标的处理方法,并没有完完全全明白win7系统桌面和控制面板里都没计算机图标是如何解决的,今天小编准备了简单的解决办法,只需要按照1.首先,进入win7家庭普通版操作系统,点击“开始”按钮 2.点击开始按钮弹出如下对话框,大家都不陌生。大家把鼠标放在计算机按钮上,右..._win7家庭版不显示电脑桌面图标
java中使用cglib和asm实现基于子类(java简单类)实现的动态代理实例+基于接口实现动态代理_javacglib基于asm-程序员宅基地
文章浏览阅读383次。动态代理的作用:在不改变源码的情况下增强方法;举个例子,在进行简单的jdbc操作的时候,你想做到每执行一次sql语句就打印一句话,作为日志.说明:本例子是基于子类(任何一个java普通类)的动态代理,(当然也有基于接口的动态代理模式了)[点击这里连接到](https://blog.csdn.net/weixin_45127611/article/details/104523192);首先定义..._javacglib基于asm
随便推点
Android 10系统及以上IMEI的获取_android10获取设备mmei-程序员宅基地
文章浏览阅读2.1k次。IMEI是一个15位的数字标识,用于唯一标识移动通信设备,例如手机、平板电脑和调制解调器等。您可以通过拨打"*#06#"(或类似的代码)来查看您的设备的IMEI号码。且每个应用的Android ID都不一样,该Android ID除非进行恢复出产设置或者刷机,否则是一直不会改变,这是Google处于隐私考虑,提供给应用开发者一个临时长期的唯一识别码(广告ID)在Android10系统,正常情况下是不允许直接获取到IMEI,而是由系统生成一串虚拟的Android ID。_android10获取设备mmei
java exception 级别_Java异常体系概述-程序员宅基地
文章浏览阅读397次。Java的异常体系结构Java异常体系的根类是 Throwable, 所以当写在java代码中写throw抛出异常时,后面跟的对象必然是Throwable或其子类的对象。其中Exception异常是指一些可以恢复的异常, 例如常见的NullPointerException空指针异常。Error指的是一些致命的错误,无法通过程序代码手段恢复的异常,例如OutOfMemoryError内存溢出错误。u..._exception等级
MATLAB---matlab 中的bwlabel函数_matlab bwlabel函数-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏5次。用法:L = bwlabel(BW,n) 返回一个和BW大小相同的L矩阵,包含了标记了BW中每个连通区域的类别标签,这些标签的值为1、2、num(连通区域的个数)。n的值为4或8,表示是按4连通寻找区域,还是8连通寻找,默认为8。 四连通或八连通是图像处理里的基本感念:8连通,是说一个像素,如果和其他像素在上、下、左、右、左上角、左下角、右上角或右下角连接着_matlab bwlabel函数
网络安全常见十大漏洞总结(原理、危害、防御)-程序员宅基地
文章浏览阅读803次,点赞30次,收藏8次。接下来我将给各位同学划分一张学习计划表!
RS485或RS232转ETHERCAT连接ethercat转换器_rs422转ethercat-程序员宅基地
文章浏览阅读359次。捷米JM-ECT-RS485/232来了!这是一款自主研发的ETHERCAT从站功能的通讯网关,主要功能是将ETHERCAT网络和RS485或RS232设备连接起来。它连接到ETHERCAT总线中做为从站使用,连接到RS485或RS232总线中做为主站或从站使用,解决了协议不兼容的问题_rs422转ethercat
ChatGPT有使用次数限制吗-程序员宅基地
文章浏览阅读2.8k次。ChatGPT是一种聊天机器人模型,由OpenAI开发。这种模型是开放源代码的,并提供了多种使用方式。我不知道你是想使用ChatGPT的哪种方式,因此无法回答你的问题。但是,一般来说,开源软件通常不会有使用次数限制。如果你使用的是OpenAI提供的某种云服务来使用ChatGPT,那么可能会有使用限制。你可以参考OpenAI的文档或者提问给它们,了解更多有关使用限制的信息。..._chatgpt3.5有使用数量限制吗