hive(一)hive的安装与基本配置_hive安装与配置详解-程序员宅基地
技术标签: hive
目录
一、前提:
安装hive所需要的虚拟机环境为虚拟机安装有Hadoop并且集群成功,同时Hadoop需要在启动状态下,同时需要安装有mysql。不需要有zookeeper和HA,由于HA中含有大量进程,启动会占用很多资源,建议不要有HA
二、安装步骤:
1、上传jar包至/usr/local/soft
将hive-3.1.2上传到虚拟机中的/usr/local/soft目录下
2、解压并重命名
tar -zxvf apache-hive-3.1.2-bin.tar.gz
# 重命名
mv apache-hive-3.1.2-bin hive-3.1.2/
3、配置环境变量
vim /etc/profile
#增加以下内容:
# HIVE_HOME
export HIVE_HOME=/usr/local/soft/hive-3.1.2/
export PATH=$PATH:$HIVE_HOME/bin
#保存退出 source 使其生效
source /etc/profile
三、配置HIVE文件
1、配置hive-env.sh
cd $HIVE_HOME/conf
# 复制命令
cp hive-env.sh.template hive-env.sh# 编辑
vim hive-env.sh# 增加如下内容
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/local/soft/hive-3.1.2/conf
2、配置hive-site.xml
上传hive-site.xml到conf目录:
hive-site.xml文件内容:
<configuration>
<property>
<!-- 查询数据时 显示出列的名字 -->
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<!-- 在命令行中显示当前所使用的数据库 -->
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<!-- 默认数据仓库存储的位置,该位置为HDFS上的路径 -->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 8.x -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=GMT</value>
</property>
<!-- 8.x -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- hiveserver2服务的端口号以及绑定的主机名 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>master</value>
</property>
</configuration>3、配置日志
# 创建日志目录
cd $HIVE_HOME
mkdir log# 设置日志配置
cd confcp hive-log4j2.properties.template hive-log4j2.properties
vim hive-log4j2.properties
# 修改以下内容:
property.hive.log.dir = /usr/local/soft/hive-3.1.2/log
4、修改默认配置文件
cp hive-default.xml.template hive-default.xml
5、上传MySQL连接jar包
上传 mysql-connector-java-5.1.37.jar 至 /usr/local/soft/hive/lib目录中
四、修改MySQL编码
修改mysql编码为UTF-8:
1、 编辑配置文件
vim /etc/my.cnf
2、加入以下内容:
[client]
default-character-set = utf8mb4
[mysqld]
character-set-server = utf8mb4
collation-server = utf8mb4_general_ci
3、 重启mysql
systemctl restart mysqld
五、初始化HIVE
schematool -dbType mysql -initSchema
六、进入hive
输入命令:hive
七、后续配置
修改mysql元数据库hive,让其hive支持utf-8编码以支持中文
登录mysql:
mysql -u root -p123456
切换到hive数据库:
use hive;
1).修改字段注释字符集
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
2).修改表注释字符集
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
3).修改分区表参数,以支持分区键能够用中文表示
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
4).修改索引注解(可选)
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
5).修改库注释字符集
alter table DBS modify column DESC varchar(4000) character set utf8;
八、测试hive
启动hive,直接输入命令:hive
在hive中创建filetest数据库
命令: create database filetest;
切换filetest数据库:use filetest;
hive中的几种存储格式
TextFile格式:文本格式
以TextFile格式创建students表:
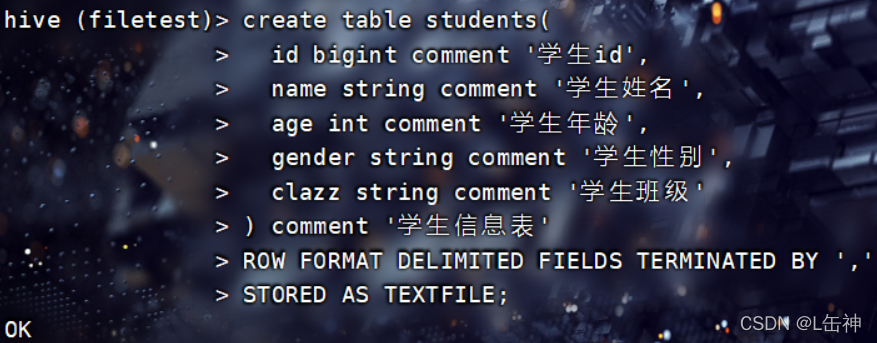
使用命令:desc students查看students表的各个字段:
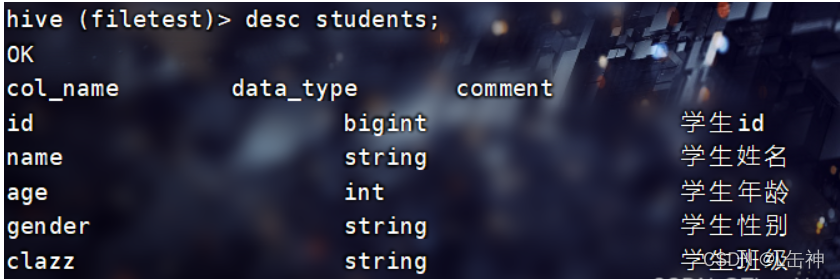
在hive根目录下创建一个文件夹data用于存放本地文件,将本地中的一个文本文件上传到hive根目录下的data中
向表中插入数据:
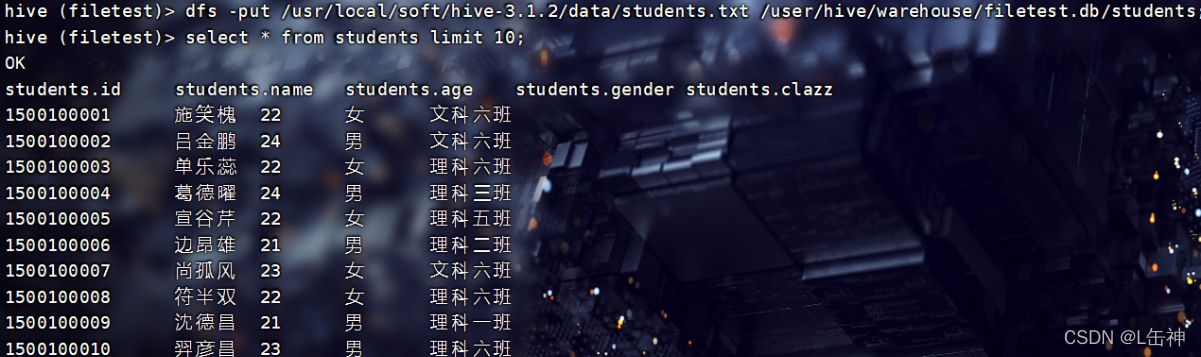
1、通过input命令将该data中的文本文件上传到hdfs中所创建的该表中,实现向该表中插入数据
在hive中可以使用hdfs中的命令:
查询结果:
2、通过普通的格式对表中进行插入数据
创建一个新的表stduents2,使用普通格式进行插入数据:
load data local inpath "/usr/local/soft/hive-3.1.2/data/students.txt" into table students2;
结果:

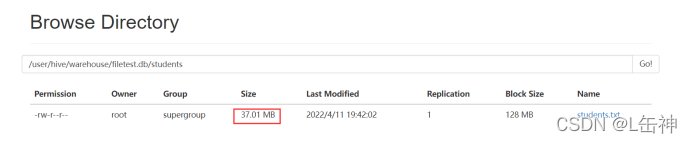
进入到hdfs中查看:发现两种插入方式对数据大小没有变化,都是37M:
RCFile:
Hadoop中第一个列文件格式
RCFile通常写操作较慢,具有很好的压缩和快速查询功能。
创建RCFile格式的表:
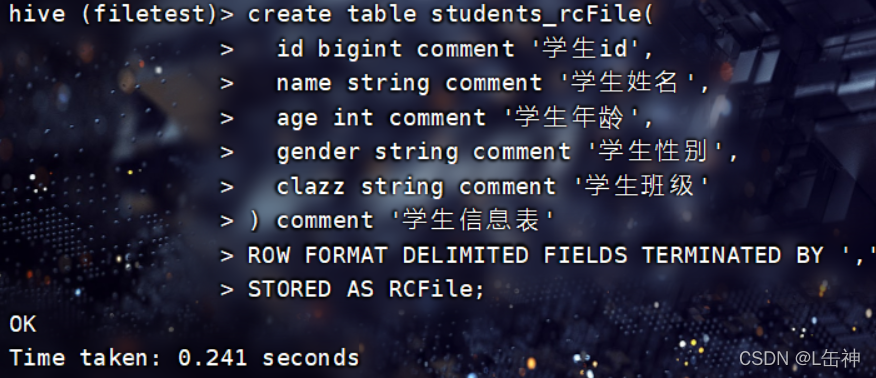
插入数据:
使用命令:
insert into table students_rcFile select * from students;
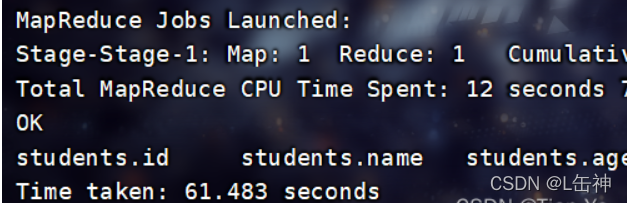
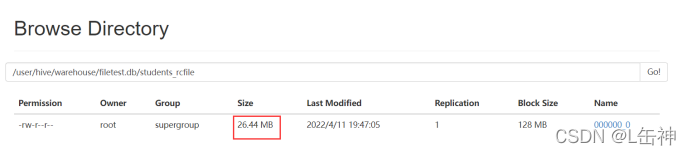
插入完成后,查看数据大小:为26.44M
ORCFile:
Hadoop0.11版本就存在的格式,不仅是一个列文件格式,而且有着很高的压缩比
创建ORCFile格式的表:
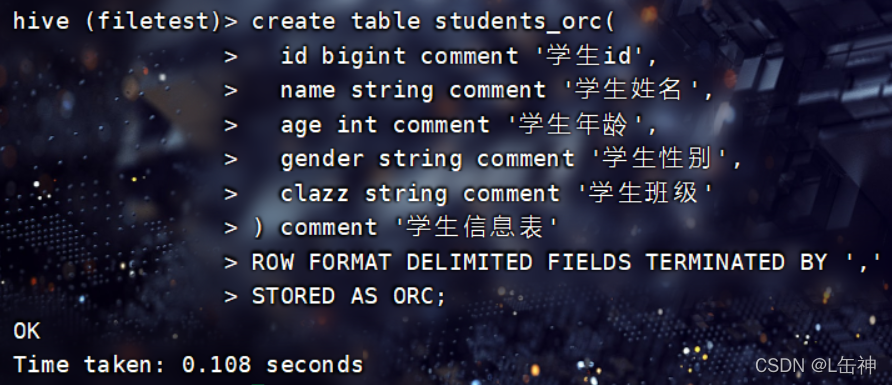
向表中插入数据:
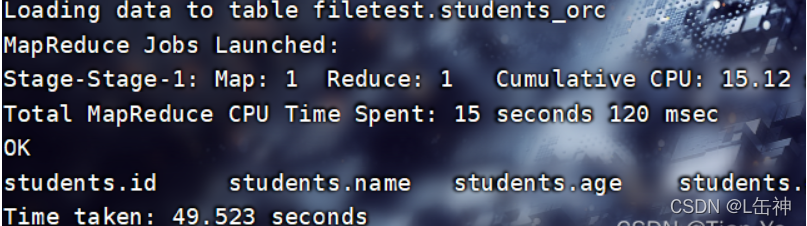
查看数据大小:被压缩为220.38KB

同时观察插入数据所用时间,ORCFile格式与RCFile格式插入数据相差时间不大
Parquet:
这是一种嵌套结构的存储格式,他与语言、平台无关
创建Parquet格式的表:
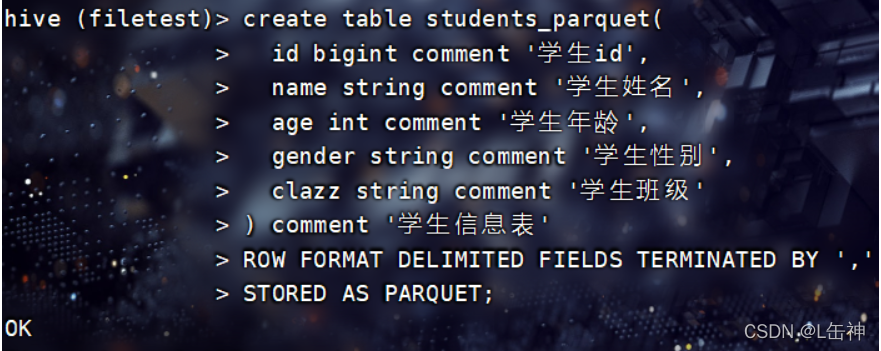
向表中插入数据:
insert into table students_parquet select * from students;
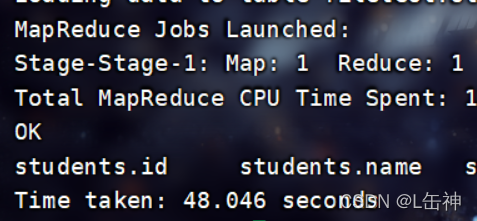
查看数据大小:为3M
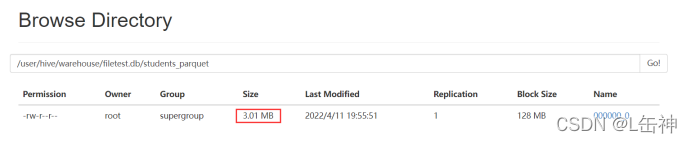
同时发现该格式在插入数据时所花费的时间比ORC格式所花费的时间更少。
其他格式:
SEQUENCEFILE格式:这是一个Hadoop API提供的一种二进制文件格式,实际生产中不使用
AVRO:是一种支持数据密集型的二进制文件格式,他的格式更为紧凑
九、配置JDBC连接
Hive中有两种命令模式:CLi模式和JDBC模式
Cli模式就是Shell命令行
JDBC模式就是Hive中的Java,与使用传统数据库JDBC的方式类似
开启JDBC连接:
进入到/usr/local/soft/hive-3.1.2/bin目录下,在bin目录下有一个hiveserver2文件,通过该文件开启JDBC连接:
输入命令:hive --service hiveserver2开启JDBC连接
一般情况下当出现四个Hive Session时就说明JDBC连接被开启了,也可以通过命令查看是否开启:
进入到 /usr/local/soft/hive-3.1.2/bin目录下:
输入:netstat -nplt | grep 10000
该输入的端口号为hive-site.xml中的hiveserver2服务的端口号
报错:
若输入该命令报错:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://master:10000:
Failed to open new session: java.lang.RuntimeException:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):
User: root is not allowed to impersonate root (state=08S01,code=0)
解决办法:
先关闭Hadoop集群:stop-all.sh
再进入到Hadoop 中的core-site.xml中添加如下内容:
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
#以下是添加的内容:
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>注意:这些内容需要添在加<configuration>...</configuration>中,否则无法生效
重新启动集群:start-all.sh
再次启动hiveserver2
hive --service hiveserver2
该过程较慢,需要等待
连接到JDBC
当启动JDBC连接后,会开启一个进程RunJar,使用jps命令就可查看
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby
连接到JDBC命令:
进入到 /usr/local/soft/hive-3.1.2/bin下,输入命令:
beeline -u jdbc:hive2://master:10000 -n root连接JDBC:
在JDBC中输入命令可以查看当前hive中的数据库:show databases;
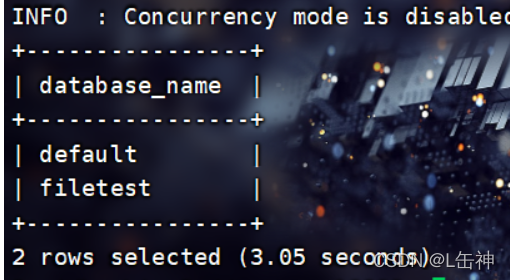
可以发现他与hive的区别在于他使用了一个表格式将databases显示出来
Hive中metastore是hive元数据的集中存放地,这里使用的是MySQL
智能推荐
L2-039 清点代码库 - java_l2-039 清点代码库 java-程序员宅基地
文章浏览阅读7.6k次。L2-039 清点代码库 (25 分)Java (javac)时间限制1500 ms内存限制128 MBPython (python3)时间限制1500 ms内存限制64 MB其他编译器时间限制500 ms内存限制64 MB上图转自新浪微博:“阿里代码库有几亿行代码,但其中有很多功能重复的代码,比如单单快排就被重写了几百遍。请设计一个程序,能够将代码库中所有功能重复的代码找出。各位大佬有啥想法,我当时就懵了,然后就挂了。。。”这里我们把问题简化一下:首先假设两个功能模_l2-039 清点代码库 java
PTA:完全二叉搜索树 (25 分)_完全二叉搜索树 分数 10 作者 陈越 单位 浙江大学 一个无重复的非负整数序列,必定-程序员宅基地
文章浏览阅读922次,点赞2次,收藏6次。题目详情:一个无重复的非负整数序列,必定对应唯一的一棵形状为完全二叉树的二叉搜索树。本题就要求你输出这棵树的层序遍历序列。输入格式:首先第一行给出一个正整数N(≤1000),随后第二行给出N个不重复的非负整数。数字间以空格分隔,所有数字不超过 2000。输出格式:在一行中输出这棵树的层序遍历序列。数字间以 1 个空格分隔,行首尾不得有多余空格。输入样例:101 2 3 4 5 6 7 8 9 0结尾无空行输出样例:6 3 8 1 5 7 9 0 2 4..._完全二叉搜索树 分数 10 作者 陈越 单位 浙江大学 一个无重复的非负整数序列,必定
[2020.8.3]联想 ZUK Z1 Magisk ROOT 纯净无推广 一键刷机 ZUI_-程序员宅基地
文章浏览阅读72次。教程本刷机包比一般的大,是因为同时适配recovery卡刷和酷卓一键刷机。但是刷进系统后和普通刷机包都是一样的。注意事项(务必细读) 联想 ZUK Z1 免解锁BL(bootloader),一键ROOT是保资料的,刷机是会清空数据的(无论如何都请备份重要数据)卡刷方法卡刷需要已经安装了twrp recovery,直接传入手机后用twrp recovery刷机,和普通刷机包使用无区别..._zukz1被root了怎么办
数据结构与算法分析 3.26 — 双端队列的实现-程序员宅基地
文章浏览阅读590次。一、题目 编写支持双端队列的例程,插入与弹出操作均花费 O(1)时间二、解答 双端队列(deque,全名double-ended queue)是一种具有队列和栈性质的数据结构。 双端队列中的元素可以从两端弹出,插入和删除操作限定在队列的两边进行。 基本操作:在双端队列两端插入与删除。 ADT术语: ..._编写算法实现双端队列。数据结构分析
centos7安装clion_clion centos-程序员宅基地
文章浏览阅读4.2k次。centos7安装clion下载clion的linux包。上传到linux服务器下。scp -P 20211 E:\迅雷下载\cmake-3.14.3.tar.gz 用户名@服务器地址:/home/bob/解压并到解压的文件夹bin目录下。运行命令“./clion.sh”。(需在centos7图形界面模式下才能启动clion)启动之后还不能运行c语言程序,我们还需要安装gcc、..._clion centos
jetson nano——编译安装Qt_jetson编译安装qt-程序员宅基地
文章浏览阅读1.3k次,点赞18次,收藏21次。1.Qt 的可执行文件目录,通常是 /usr/local/Qt-5.15.2/bin,其中 5.15.2 是你安装的 Qt 版本号。链接:https://pan.baidu.com/s/1at9aW5-Q-wBNIIk5wRLM6A?3.Qt 的插件目录,通常是 /usr/local/Qt-5.15.2/plugins。2.Qt 的库文件目录,通常是 /usr/local/Qt-5.15.2/lib。_jetson编译安装qt
随便推点
linux上修改php.ini配置添加扩展时不生效_php.ini加入了extension 不生效-程序员宅基地
文章浏览阅读2.1k次。因初次编译安装php时没有开启openssl, 导致请求https网站报错, 为此需要手动编译openssl扩展然后添加到php.ini中. 问题就在自己明明已经编译安装生成openssl.so的步骤都没有错, 也已经将extension=openssl.so加入php.ini中,服务器也重启了, 但是无论是访问phpinfo()打印的出内容还是直接命令行php -m打印加载的模块都没有显示有加载..._php.ini加入了extension 不生效
linux中如何建立连接文件_linux建立文件链接-程序员宅基地
文章浏览阅读8.1k次。这是linux中一个非常重要命令,请大家一定要熟悉。它的功能是为某一个文件在另外一个位置建立一个同不的链接,这个命令最常用的参数是-s,具体用法是:ln -s 源文件 目标文件。当 我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在其它的 目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间..._linux建立文件链接
Kafka在Windows安装运行_kafak windows版-程序员宅基地
文章浏览阅读5.2w次,点赞27次,收藏102次。摘要:本文主要说明了如何在Windows安装运行Kafka_kafak windows版
formatter是什么?-程序员宅基地
文章浏览阅读4.3k次,点赞2次,收藏11次。element里面表格的一个属性 formatter 叫格式化内容的_formatter
(MIT6.828) 1.实验环境搭建_mit6.828实验是否能在虚拟机上完成-程序员宅基地
文章浏览阅读897次。(MIT6.828) 1.实验环境搭建参考官网:https://pdos.csail.mit.edu/6.828/2018/tools.html在ubuntu14中安装x86模拟器QEMU.1. 检查工具链objdump -i会看到elf32-i386等信息gcc -m32 -print-libgcc-file-name会看到/usr/lib/gcc/i486-linux-gnu..._mit6.828实验是否能在虚拟机上完成
c17 语言标准,官宣:MSVC新加入C11和C17标准-程序员宅基地
文章浏览阅读115次。原标题:官宣:MSVC新加入C11和C17标准官宣我们很高兴的宣布,从Visual Studio 2019 v16.8 Preview 3开始,C11和C17这两个C语言版本将加入到MSVC编译器工具集(toolset)。多年以来,Visual Studio仅仅是因为C++的需要才对C进行有限度的支持。现在,事情有转变了:我们在编译器中添加了一个基于token的规范化预处理器,借助于两项新加入的编..._msvc vla