CAFFE源码学习笔记之内积层-inner_product_layer_caffe innerproduct-程序员宅基地
技术标签: CAFFE源码
一、前言
内积层实际就是全连接。经过之前的卷积层、池化层和非线性变换层,样本已经被映射到隐藏层的特征空间之中,而全连接层就是将学习到的特征又映射到样本分类空间。虽然已经出现了全局池化可以替代全连接,但是仍然不能说全连接就不能用了。
二、源码分析
1、成员变量
全连接的输入时一个M*K的矩阵,权重是K*N的矩阵,所以输出是一个M*N的矩阵
int M_;//num_input
int K_;//C*H*W
int N_;//N_ = num_output
bool bias_term_;
Blob<Dtype> bias_multiplier_;
bool transpose_; ///< if true, assume transposed weights```
2、layersetup
权重是K*N的矩阵:(C*H*W)*num_output
template <typename Dtype>
void InnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int num_output = this->layer_param_.inner_product_param().num_output();//输出
bias_term_ = this->layer_param_.inner_product_param().bias_term();
transpose_ = this->layer_param_.inner_product_param().transpose();
N_ = num_output;
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
// Dimensions starting from "axis" are "flattened" into a single
// length K_ vector. For example, if bottom[0]'s shape is (N, C, H, W),
// and axis == 1, N inner products with dimension CHW are performed.
K_ = bottom[0]->count(axis);
// Check if we need to set up the weights
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
if (bias_term_) {
this->blobs_.resize(2);
} else {
this->blobs_.resize(1);
}
// Initialize the weights
vector<int> weight_shape(2);
if (transpose_) {
weight_shape[0] = K_;
weight_shape[1] = N_;
} else {
weight_shape[0] = N_;
weight_shape[1] = K_;
}
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
// fill the weights
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
// If necessary, intiialize and fill the bias term
if (bias_term_) {
vector<int> bias_shape(1, N_);
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
} // parameter initialization
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
3、reshape
输入是一个M*K的矩阵:num_input*(C*H*W)
经过转换:top_shape.resize(axis + 1)
输出是M*N的矩阵:
num_input∗num_output
template <typename Dtype>
void InnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// Figure out the dimensions
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
const int new_K = bottom[0]->count(axis);
CHECK_EQ(K_, new_K)
<< "Input size incompatible with inner product parameters.";
// The first "axis" dimensions are independent inner products; the total
// number of these is M_, the product over these dimensions.
M_ = bottom[0]->count(0, axis);//num_input
// The top shape will be the bottom shape with the flattened axes dropped,
// and replaced by a single axis with dimension num_output (N_).
vector<int> top_shape = bottom[0]->shape();
top_shape.resize(axis + 1);
top_shape[axis] = N_;
top[0]->Reshape(top_shape);
// Set up the bias multiplier
if (bias_term_) {
vector<int> bias_shape(1, M_);
bias_multiplier_.Reshape(bias_shape);
caffe_set(M_, Dtype(1), bias_multiplier_.mutable_cpu_data());
}
}
3、前向计算
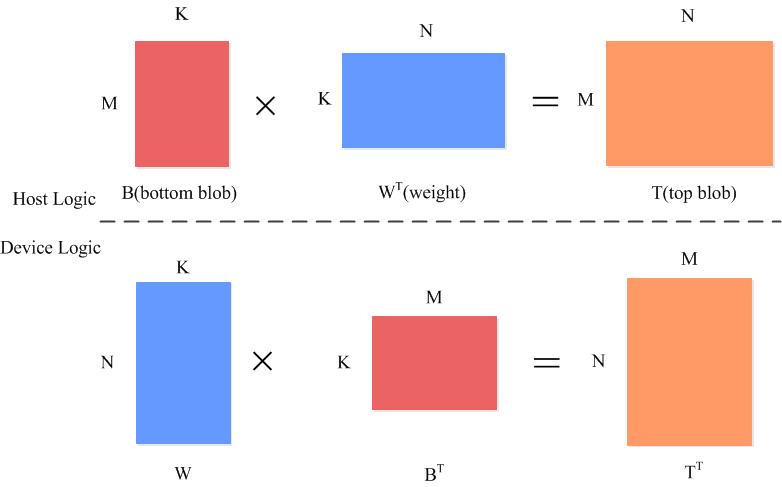
直接调用矩阵内积函数caffe_gpu_gemm
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->gpu_data();
Dtype* top_data = top[0]->mutable_gpu_data();
const Dtype* weight = this->blobs_[0]->gpu_data();
if (M_ == 1) {
caffe_gpu_gemv<Dtype>(CblasNoTrans, N_, K_, (Dtype)1.,weight, bottom_data, (Dtype)0., top_data);//这个是向量内积函数
if (bias_term_)
caffe_gpu_axpy<Dtype>(N_, bias_multiplier_.cpu_data()[0],this->blobs_[1]->gpu_data(), top_data);
} else {
caffe_gpu_gemm<Dtype>(CblasNoTrans,transpose_ ? CblasNoTrans : CblasTrans,M_, N_, K_, (Dtype)1.,bottom_data, weight, (Dtype)0., top_data);
if (bias_term_)
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, N_, 1, (Dtype)1.,bias_multiplier_.gpu_data(),this->blobs_[1]->gpu_data(), (Dtype)1., top_data);
}
}4、反向传播
对参数求偏导
∂loss∂wkj=∂loss∂zk∗∂zk∂wkj=∂loss∂zk∗uj
转换成向量:
∂loss∂Wj==∂loss∂Z∗uj
转换成矩阵:
∂loss∂W==∂loss∂ZT∗U
即 layer_blobs_=topdiff∗bottom_data
对输出求偏导:
公式:
∂loss∂uj=∑n=Mk∂loss∂zk∗∂zk∂uj
转化为向量
∂loss∂UT=∂loss∂ZT∗W
M为需要分的类别数
转换成矩阵的形式:
∂loss∂U=∂loss∂Z∗W
即
bottom_diff=top_diff∗layer_blobs_
template <typename Dtype>
void InnerProductLayer<Dtype>::Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (this->param_propagate_down_[0]) {
const Dtype* top_diff = top[0]->gpu_diff();
const Dtype* bottom_data = bottom[0]->gpu_data();
// Gradient with respect to weight
if (transpose_) {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
K_, N_, M_,
(Dtype)1., bottom_data, top_diff,
(Dtype)1., this->blobs_[0]->mutable_gpu_diff());
} else {
caffe_gpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
N_, K_, M_,
(Dtype)1., top_diff, bottom_data,
(Dtype)1., this->blobs_[0]->mutable_gpu_diff());
}
}
if (bias_term_ && this->param_propagate_down_[1]) {
const Dtype* top_diff = top[0]->gpu_diff();
// Gradient with respect to bias
caffe_gpu_gemv<Dtype>(CblasTrans, M_, N_, (Dtype)1., top_diff,
bias_multiplier_.gpu_data(), (Dtype)1.,
this->blobs_[1]->mutable_gpu_diff());
}
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->gpu_diff();
// Gradient with respect to bottom data
if (transpose_) {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->gpu_data(),
(Dtype)0., bottom[0]->mutable_gpu_diff());
} else {
caffe_gpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->gpu_data(),
(Dtype)0., bottom[0]->mutable_gpu_diff());
}
}
}智能推荐
874计算机科学基础综合,2018年四川大学874计算机科学专业基础综合之计算机操作系统考研仿真模拟五套题...-程序员宅基地
文章浏览阅读1.1k次。一、选择题1. 串行接口是指( )。A. 接口与系统总线之间串行传送,接口与I/0设备之间串行传送B. 接口与系统总线之间串行传送,接口与1/0设备之间并行传送C. 接口与系统总线之间并行传送,接口与I/0设备之间串行传送D. 接口与系统总线之间并行传送,接口与I/0设备之间并行传送【答案】C2. 最容易造成很多小碎片的可变分区分配算法是( )。A. 首次适应算法B. 最佳适应算法..._874 计算机科学专业基础综合题型
XShell连接失败:Could not connect to '192.168.191.128' (port 22): Connection failed._could not connect to '192.168.17.128' (port 22): c-程序员宅基地
文章浏览阅读9.7k次,点赞5次,收藏15次。连接xshell失败,报错如下图,怎么解决呢。1、通过ps -e|grep ssh命令判断是否安装ssh服务2、如果只有客户端安装了,服务器没有安装,则需要安装ssh服务器,命令:apt-get install openssh-server3、安装成功之后,启动ssh服务,命令:/etc/init.d/ssh start4、通过ps -e|grep ssh命令再次判断是否正确启动..._could not connect to '192.168.17.128' (port 22): connection failed.
杰理之KeyPage【篇】_杰理 空白芯片 烧入key文件-程序员宅基地
文章浏览阅读209次。00000000_杰理 空白芯片 烧入key文件
一文读懂ChatGPT,满足你对chatGPT的好奇心_引发对chatgpt兴趣的表述-程序员宅基地
文章浏览阅读475次。2023年初,“ChatGPT”一词在社交媒体上引起了热议,人们纷纷探讨它的本质和对社会的影响。就连央视新闻也对此进行了报道。作为新传专业的前沿人士,我们当然不能忽视这一热点。本文将全面解析ChatGPT,打开“技术黑箱”,探讨它对新闻与传播领域的影响。_引发对chatgpt兴趣的表述
中文字符频率统计python_用Python数据分析方法进行汉字声调频率统计分析-程序员宅基地
文章浏览阅读259次。用Python数据分析方法进行汉字声调频率统计分析木合塔尔·沙地克;布合力齐姑丽·瓦斯力【期刊名称】《电脑知识与技术》【年(卷),期】2017(013)035【摘要】该文首先用Python程序,自动获取基本汉字字符集中的所有汉字,然后用汉字拼音转换工具pypinyin把所有汉字转换成拼音,最后根据所有汉字的拼音声调,统计并可视化拼音声调的占比.【总页数】2页(13-14)【关键词】数据分析;数据可..._汉字声调频率统计
linux输出信息调试信息重定向-程序员宅基地
文章浏览阅读64次。最近在做一个android系统移植的项目,所使用的开发板com1是调试串口,就是说会有uboot和kernel的调试信息打印在com1上(ttySAC0)。因为后期要使用ttySAC0作为上层应用通信串口,所以要把所有的调试信息都给去掉。参考网上的几篇文章,自己做了如下修改,终于把调试信息重定向到ttySAC1上了,在这做下记录。参考文章有:http://blog.csdn.net/longt..._嵌入式rootfs 输出重定向到/dev/console
随便推点
uniapp 引入iconfont图标库彩色symbol教程_uniapp symbol图标-程序员宅基地
文章浏览阅读1.2k次,点赞4次,收藏12次。1,先去iconfont登录,然后选择图标加入购物车 2,点击又上角车车添加进入项目我的项目中就会出现选择的图标 3,点击下载至本地,然后解压文件夹,然后切换到uniapp打开终端运行注:要保证自己电脑有安装node(没有安装node可以去官网下载Node.js 中文网)npm i -g iconfont-tools(mac用户失败的话在前面加个sudo,password就是自己的开机密码吧)4,终端切换到上面解压的文件夹里面,运行iconfont-tools 这些可以默认也可以自己命名(我是自己命名的_uniapp symbol图标
C、C++ 对于char*和char[]的理解_c++ char*-程序员宅基地
文章浏览阅读1.2w次,点赞25次,收藏192次。char*和char[]都是指针,指向第一个字符所在的地址,但char*是常量的指针,char[]是指针的常量_c++ char*
Sublime Text2 使用教程-程序员宅基地
文章浏览阅读930次。代码编辑器或者文本编辑器,对于程序员来说,就像剑与战士一样,谁都想拥有一把可以随心驾驭且锋利无比的宝剑,而每一位程序员,同样会去追求最适合自己的强大、灵活的编辑器,相信你和我一样,都不会例外。我用过的编辑器不少,真不少~ 但却没有哪款让我特别心仪的,直到我遇到了 Sublime Text 2 !如果说“神器”是我能给予一款软件最高的评价,那么我很乐意为它封上这么一个称号。它小巧绿色且速度非
对10个整数进行按照从小到大的顺序排序用选择法和冒泡排序_对十个数进行大小排序java-程序员宅基地
文章浏览阅读4.1k次。一、选择法这是每一个数出来跟后面所有的进行比较。2.冒泡排序法,是两个相邻的进行对比。_对十个数进行大小排序java
物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)_网络调试助手连接阿里云连不上-程序员宅基地
文章浏览阅读2.9k次。物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)其实作者本意是使用4G模块来实现与阿里云物联网平台的连接过程,但是由于自己用的4G模块自身的限制,使得阿里云连接总是无法建立,已经联系客服返厂检修了,于是我在此使用网络调试助手来演示如何与阿里云物联网平台建立连接。一.准备工作1.MQTT协议说明文档(3.1.1版本)2.网络调试助手(可使用域名与服务器建立连接)PS:与阿里云建立连解释,最好使用域名来完成连接过程,而不是使用IP号。这里我跟阿里云的售后工程师咨询过,表示对应_网络调试助手连接阿里云连不上
<<<零基础C++速成>>>_无c语言基础c++期末速成-程序员宅基地
文章浏览阅读544次,点赞5次,收藏6次。运算符与表达式任何高级程序设计语言中,表达式都是最基本的组成部分,可以说C++中的大部分语句都是由表达式构成的。_无c语言基础c++期末速成