java htmlparser 使用教程_HtmlParser基础教程-程序员宅基地
技术标签: java htmlparser 使用教程
1、相关资料
官方文档:http://htmlparser.sourceforge.net/samples.html
API:http://htmlparser.sourceforge.net/javadoc/index.html
其它HTML 解释器:jsoup等。由于HtmlParser自2006年以后就再没更新,目前很多人推荐使用jsoup代替它。
2、使用HtmlPaser的关键步骤
(1)通过Parser类创建一个解释器
(2)创建Filter或者Visitor
(3)使用parser根据filter或者visitor来取得所有符合条件的节点
(4)对节点内容进行处理
3、使用Parser的构造函数创建解释器
对于大多数使用者来说,使用最多的是通过一个URLConnection或者一个保存有网页内容的字符串来初始化Parser,或者使用静态函数来生成一个Parser对象。ParserFeedback的代码很简单,是针对调试和跟踪分析过程的,一般不需要改变。而使用Lexer则是一个相对比较高级的话题,放到以后再讨论吧。
这里比较有趣的一点是,如果需要设置页面的编码方式的话,不使用Lexer就只有静态函数一个方法了。对于大多数中文页面来说,好像这是应该用得比较多的一个方法。
4、HtmlPaser使用Node对象保存各节点信息
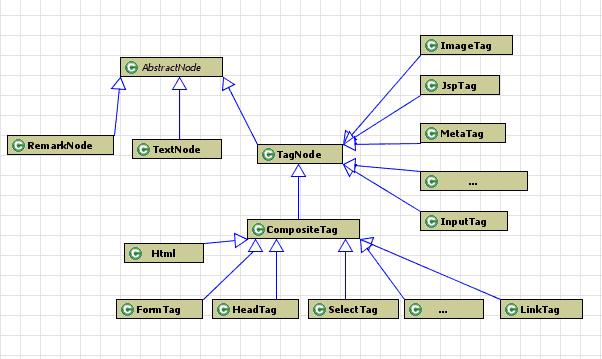
(1)访问各个节点的方法
Node getParent ():取得父节点
NodeList getChildren ():取得子节点的列表
Node getFirstChild ():取得第一个子节点
Node getLastChild ():取得最后一个子节点
Node getPreviousSibling ():取得前一个兄弟(不好意思,英文是兄弟姐妹,直译太麻烦而且不符合习惯,对不起女同胞了)
Node getNextSibling ():取得下一个兄弟节点
(2)取得Node内容的函数
String getText ():取得文本
String toPlainTextString():取得纯文本信息。
String toHtml () :取得HTML信息(原始HTML)
String toHtml (boolean verbatim):取得HTML信息(原始HTML)
String toString ():取得字符串信息(原始HTML)
Page getPage ():取得这个Node对应的Page对象
int getStartPosition ():取得这个Node在HTML页面中的起始位置
int getEndPosition ():取得这个Node在HTML页面中的结束位置
5、使用Filter访问Node节点及其内容
(1)Filter的种类
顾名思义,Filter就是对于结果进行过滤,取得需要的内容。
所有的Filter均实现了NodeFilter接口,此接口只有一个方法Boolean accept(Node node),用于确定某个节点是否属于此Filter过滤的范围。
HTMLParser在org.htmlparser.filters包之内一共定义了16个不同的Filter,也可以分为几类。
TagNameFilterHasAttributeFilter
HasChildFilter
HasParentFilter
HasSiblingFilter
IsEqualFilter
AndFilterNotFilter
OrFilter
XorFilter
NodeClassFilterStringFilter
LinkStringFilter
LinkRegexFilter
RegexFilter
CssSelectorNodeFilter
除此以外,可以自定义一些Filter,用于完成特殊需求的过滤。
(2)Filter的使用示例
以下示例用于提取HTML文件中的链接
packageorg.ljh.search.html;
importjava.util.HashSet;
importjava.util.Set;
importorg.htmlparser.Node;
importorg.htmlparser.NodeFilter;
importorg.htmlparser.Parser;
importorg.htmlparser.filters.NodeClassFilter;
importorg.htmlparser.filters.OrFilter;
importorg.htmlparser.tags.LinkTag;
importorg.htmlparser.util.NodeList;
importorg.htmlparser.util.ParserException;
//本类创建用于HTML文件解释工具
publicclassHtmlParserTool {
// 本方法用于提取某个html文档中内嵌的链接
publicstaticSet extractLinks(String url, LinkFilter filter) {
Set links = newHashSet();
try{
// 1、构造一个Parser,并设置相关的属性
Parser parser = newParser(url);
parser.setEncoding("gb2312");
// 2.1、自定义一个Filter,用于过滤标签,然后取得标签中的src属性值
NodeFilter frameNodeFilter = newNodeFilter() {
@Override
publicbooleanaccept(Node node) {
if(node.getText().startsWith("frame src=")) {
returntrue;
} else{
returnfalse;
}
}
};
//2.2、创建第二个Filter,过滤标签
NodeFilter aNodeFilter = newNodeClassFilter(LinkTag.class);
//2.3、净土上述2个Filter形成一个组合逻辑Filter。
OrFilter linkFilter = newOrFilter(frameNodeFilter, aNodeFilter);
//3、使用parser根据filter来取得所有符合条件的节点
NodeList nodeList = parser.extractAllNodesThatMatch(linkFilter);
//4、对取得的Node进行处理
for(inti =0; i
Node node = nodeList.elementAt(i);
String linkURL = "";
//如果链接类型为
if(nodeinstanceofLinkTag){
LinkTag link = (LinkTag)node;
linkURL= link.getLink();
}else{
//如果类型为
String nodeText = node.getText();
intbeginPosition = nodeText.indexOf("src=");
nodeText = nodeText.substring(beginPosition);
intendPosition = nodeText.indexOf(" ");
if(endPosition == -1){
endPosition = nodeText.indexOf(">");
}
linkURL = nodeText.substring(5, endPosition -1);
}
//判断是否属于本次搜索范围的url
if(filter.accept(linkURL)){
links.add(linkURL);
}
}
} catch(ParserException e) {
e.printStackTrace();
}
returnlinks;
}
}
程序中的一些说明:
(1)通过Node#getText()取得节点的String。
(2)node instanceof TagLink,即节点,其它还有很多的类似节点,如tableTag等,基本上每个常见的html标签均会对应一个tag。官方文档说明如下:
The nodes package has the concrete node implementations.
The tags package contains specific tags.
因此可以通过此方法直接判断一个节点是否某个标签内容。
其中用到的LinkFilter接口定义如下:
packageorg.ljh.search.html;
//本接口所定义的过滤器,用于判断url是否属于本次搜索范围。
publicinterfaceLinkFilter {
publicbooleanaccept(String url);
}
测试程序如下:
packageorg.ljh.search.html;
importjava.util.Iterator;
importjava.util.Set;
importorg.junit.Test;
publicclassHtmlParserToolTest {
@Test
publicvoidtestExtractLinks() {
String url = "http://www.baidu.com";
LinkFilter linkFilter = newLinkFilter(){
@Override
publicbooleanaccept(String url) {
if(url.contains("baidu")){
returntrue;
}else{
returnfalse;
}
}
};
Set urlSet = HtmlParserTool.extractLinks(url, linkFilter);
Iterator it = urlSet.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
输出结果如下:
http://www.hao123.com
http://www.baidu.com/
http://www.baidu.com/duty/
http://v.baidu.com/v?ct=301989888&rn=20&pn=0&db=0&s=25&word=
http://music.baidu.com
http://ir.baidu.com
http://www.baidu.com/gaoji/preferences.html
http://news.baidu.com
http://map.baidu.com
http://music.baidu.com/search?fr=ps&key=
http://image.baidu.com
http://zhidao.baidu.com
http://image.baidu.com/i?tn=baiduimage&ct=201326592&lm=-1&cl=2&nc=1&word=
http://www.baidu.com/more/
http://shouji.baidu.com/baidusearch/mobisearch.html?ref=pcjg&from=1000139w
http://wenku.baidu.com
http://news.baidu.com/ns?cl=2&rn=20&tn=news&word=
https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F
http://www.baidu.com/cache/sethelp/index.html
http://zhidao.baidu.com/q?ct=17&pn=0&tn=ikaslist&rn=10&word=&fr=wwwt
http://tieba.baidu.com/f?kw=&fr=wwwt
http://home.baidu.com
https://passport.baidu.com/v2/?reg®Type=1&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F
http://v.baidu.com
http://e.baidu.com/?refer=888
;
http://tieba.baidu.com
http://baike.baidu.com
http://wenku.baidu.com/search?word=&lm=0&od=0
http://top.baidu.com
http://map.baidu.com/m?word=&fr=ps01000
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象