性能测试瓶颈分析与系统调优(10)mysql数据库性能瓶颈分析调优_mysql性能测试瓶颈及调优-程序员宅基地
10.1数据库运行机制
数据库--本质就是一个软件系统,这个系统的功能:数据管理【增删改查】
整体结构:

从整体结构角度来看
得出两项优化方案:配置更好的内存;用更好的磁盘硬件,比如:SSD
注意点:内存并不是保存所有数据,只是说mysql在操作数据的时候,需要先加载到内存
压测数据库性能:用jmeter进行压测
纯粹的测试人员只能做数据库的基准测试:增删改查基本操作,涉及关联
性能指标、测试报告、瓶颈分析--和应用程序压测一样
10.2数据库监控体系
10.2.1服务器本上的监控
linux服务器监控,所有参与到性能测试的服务都要监控
10.2.2Mysql独立的监控指标
部署运行数据运行信息的采集脚本服务
在prometheus官网,下载mysqld_exporter
下载地址:https://prometheus.io/download/#mysqld_exporter

将文件放到mysql服务器的文件夹中,解压
tar -zxvf mysqld_exporter-0.14.0.linux-amd64.tar.gz
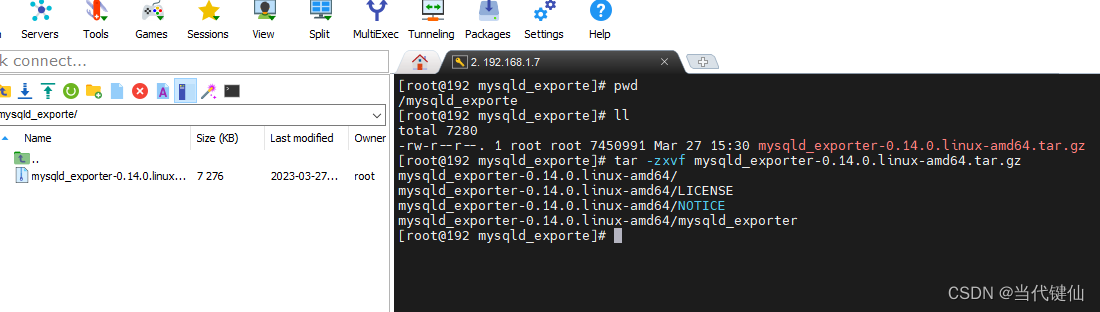
运行:
配置要监控的数据库信息:
export DATA_SOURCE_NAME=’root:zhaoWEILI1314520@@(192.168.1.7:3306)/’
其中:root为数据库用户名
zhaoWEILI1314520@为密码,后面加@(数据库ip地址:3306)/

建议:单独创建账户,用于获取mysql的运行信息
运行mysql_export服务:
前台运行: ./mysqld_exporter

后台运行 nohup ./mysqld_exporter >mysql_exporter.log 2>&1 &
默认9104网络单口用于查询数据库采集信息,给Prometheus调用
设置防火墙开放9104端口策略
firewall-cmd --add-port=9104/tcp --permanent
firewall-cmd - -reload
测试是否配置成功,在浏览器输入数据库地址加端口号9104

在grafana服务器上,配置Prometheus采集任务,修改配置文件

Prometheus和数据库服务/采集服务器网络要通畅
修改之后,后台启动Prometheus任务
nohup
/prometheus/prometheus-2.41.0.linux-amd64/prometheus --config.file=prometheus.yml >prometheus.log 2>&1 &

配置grafana监控看板,在grafana下载mysql插件
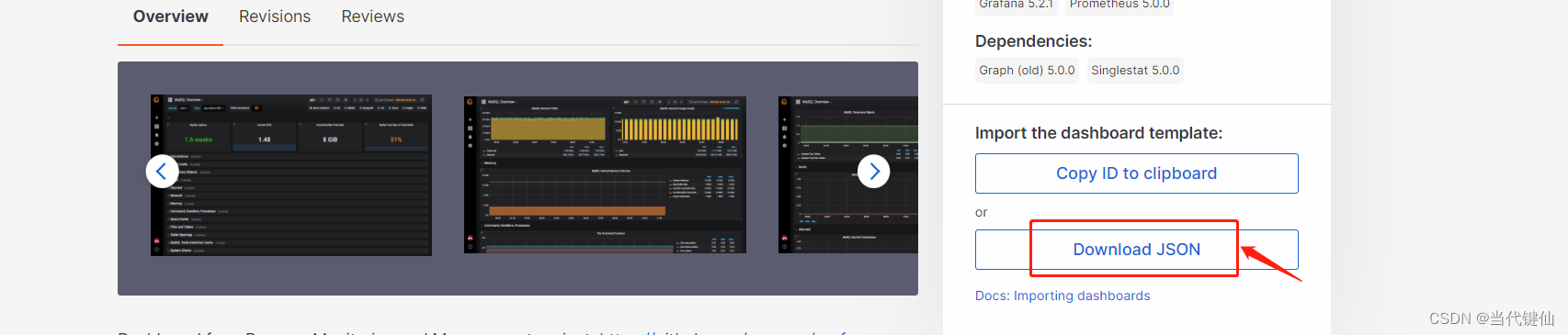

导入监控看板,bug修复

#修改了json模板文件内Buffer Pool Size of Total RAM这个展示的数据查询表达式

"expr": "(label_replace(mysql_global_variables_innodb_buffer_pool_size{instance=
\"$host\"}, \"nodename\", \"$1\", \"instance\", \"(.*):.*\") * 100) / on
(nodename) (label_replace(node_memory_MemTotal_bytes, \"nodename\", \"$1\", \"instance\",
没有修改的话,这里是没有数据的

注意:这个内容的展示,有一个前提:你的把mysql所在的服务linux监控起来,这样才能看到数据。因为这个地方是用到mysql自身的内存/机器内存,计算出来的

10.3数据库事务机制
10.3.1ACID描述
ACID模型是一组数据库设计原则,对于事务型应用程序非常重要。
Atomicit原子性:事务通常有多个语句组成。原子性保证将每个事务是为一个“单元”,该事务要么完全成功,要么完全失败
Consistency一致性:事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态
lsolation隔离性:通常数据库会有多个事务同时执行,隔离可确保事务的并发执行不会相互干扰。
Durability持久性:持久性保证一旦事务被提交,即使在系统故障(例如,停电或崩溃)的情况下,事务也要保持提交状态
10.3.2事务
一件事可能有多个步骤组成
一个或者多个SQL的执行
明确开始和结束
begin:开始事务
commit:提交事务
rollback:回滚事务
注意事项:性能测试后,要检查数据的正确性
高并发系统--系统BUG,对于数据的处理出现问题
结合业务场景和开发去确定
10.4数据库锁机制
查看锁等待信息

表锁:当事务真正该使用一张表的时候,数据库会给这个表加一把锁
另外一个事务需要对这个表进行操作(删除并、修改版),不好意思,此时--等待其它事务释放锁
行锁:某一行,某部分的数据被锁住
10.5数据库调优思路汇总
10.5.1发现瓶颈
资源不够用:CPU、网络资源、磁盘资源、内存
响应时间--慢查询日志:该日志记录执行时间超过阈值的sql语句
注意:慢查询日志并不仅仅只记录select,update这种数据修改的SQL语句执行过长也会被记录
配置:slow_query_log 是否启用
slow_query_log_file日志文件
Long_query_time 以慢SQL的阈值(根据业务系统而定)
log_queries_not_using_indexes:是否记录未使用索引的SQL。(建议开启)
性能测试期间,可以临时开启查看是否开启:show variables like “%slow_query_log”;
OFF为关闭ON为开启,开启: set global slow_query_log=1

开启:set global long_query_time =0.001
在数据库服务器上打开查看这个文件:tail -f /var/lib/mysql/localhost-slow.log

超过这个时间的,都会被记录,这里设置了0.001s,理论所有的sql语句都会被记录
日志说明:

10.5.2连接数据库
程序性能跟不上,数据库CPU占用很高、或者CPU占用很低
每一个网络连接-执行SQL,数据库都会有对应线程来处理,创建的连接过多,cpu占用高
连接池:应用程序,基本都会采用数据库连接池
类似线程池,但是有点不一样:因为数据库对外是通过网络进行操作
网络连接涉及到连接创建、销毁--如果每一次操作数据都是重新创建连接,程序的性能下降
应用程序和数据库的关系大多数情况下是绑定,数据库操作很频繁。
所以:能不能把数据网络连接进行复用???--可以的,连接池
创建多个网络连接,不中断
过多:导致数据压力变大,处理变慢
过少:程序响应时间会变慢,因为需要消耗大量的时间去等待数据库连接的释放
综合之前将tomcat/web服务器线程概念去理解
如何发现程序是因为书库等待而导致的响应过慢?
需要调整参数进行--配置测试
如果开发愿意配合,从应用程序角度去做数据库操作的监控
比如Druid连接池技术

10.5.3数据库内存
Innodb_buffer_pool_size 服务器内存80%
sql语句:show variables like "%pool%"
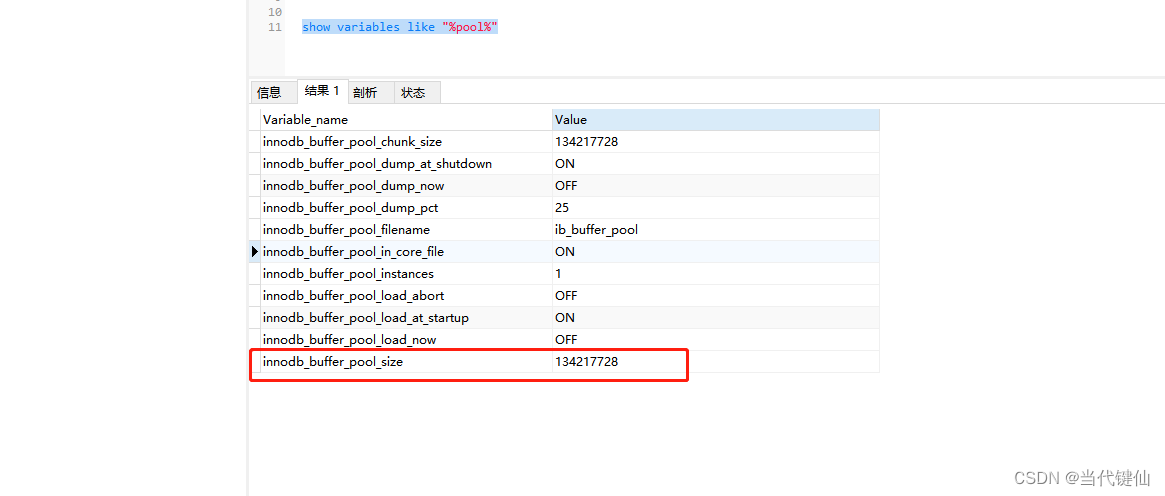
数据库一般都是独立部署运行
服务器的内存,基本上80%都会给数据库
10.5.4 sql语句
查询-调优分析
尽量用到索引:
对应筛选条件,没建立索引,那就不会用到索引
数据量比较小,创建了索引不一定会用到索引,数据库本身有优化机制
执行计划:如何检测SQL语言用到索引
数据库功能:查看执行计划
EXPLAIN<select statement>;
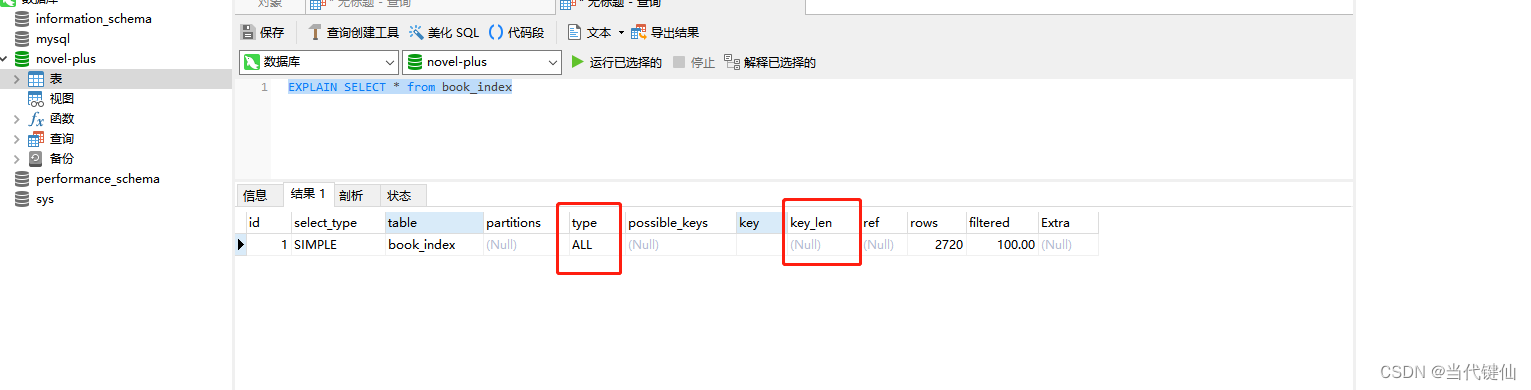
执行计划内容

只要看执行计划--Type

索引最好的状态就是以下三种:
consts单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据
ref指的是使用普通的索引(normal index)。
range对索引进行范围检索
下面这三种都比较慢
type=index,索引物理文件全扫描,速度非常慢,这个index级别比较range还低。与全表扫描是小巫见大巫
尽量避免查询不需要的数据,查询需要的信息:
避免:select *
实际业务场景,可能只需要记录的部分字段
原因:查询不需要的数据--占内存、网络宽带,最终影响响应时间、吞吐量
避免大量的表关联join:一条sql查询,涉及的表越多,SQL越慢,阿里巴巴内部:禁止出现3张表以上的关联查询
搜索场景严禁左模糊或者全模糊:like模糊查询可能导致索引失效
注意点:不是所有的like语句都不走索引,例如:右模糊
功能设置:不论表大小,都要加上分页的参数:防止后续数据库,表数据增加,而产生性能问题。
性能测试-针对未来的某个场景,模拟未来表数据增加之后,系统是否能够支撑
更新:
非必要,不要主动锁数据
数据库提供SQL语句,主要缩表/锁记录,如果因为数据被锁,而导致请求变慢【监控数据库锁等待信息】检测锁等情况
及时关闭事务:事务会导致数据库锁表/锁数据情况,操作完数据库之后,没有即使关闭事务,可能导致其他操作数据的变慢
大量更新可以用批处理:
业务场景:数据导入功能,数据批量删除/修改
数据库--批量执行多条SQL语句,插入--values sql
10.5.5表结构
开发怼你:SQL语句只能这么些,没法改了
设计表的时候。就要考虑索引:数据量非常大的时候,创建索引是很慢的,创建索引也可能导致数据变卡
表结果可以适当做一些冗余:字段允许适当冗余,以提高查询性能,但必须考虑数据一直。冗余字段应遵循:
不是频繁修改的字段;不是varchar超长字段,更不能是text字段;
正例:商品类目名称使用频率搞,字段长度短,名称基本一成不变,可在相关联的表中冗余存储类目名称,避免关联查询
缺点:字段修改的时候会涉及多个表很麻烦,而且占用更多空间,这就是性能优化的取舍
触发器、主外键,高并发下避免使用
触发器:当我们执行数据操作的时候,触发数据库里面设定好存储过程的时候/用户自定义功能的执行
主外键:当我们进行数据变更的时候,数据库会去额外进行主外键检测
主外键的目的:是为了确保数据的正确性,例如:员工表里面的部门ID字段和部门表的ID字段一一对应
数据的正确应该交给应用程序去维护(业务逻辑),而不是交给数据库,因为数据库的性能不高:删除部门之前,程序先查询部门下是否有员工,尽量少让数据库干活
表字段类型尽量和使用时需要的类型相匹配,避免无所谓的类型转换
10.5.5架构优化
单台数据库服务器,在面临海量的数据,海里的请求情况下,肯定是由上限
集群架构:用多台服务器;部署多个数据服务器;从开发调用的角度,依然是像一台服务机器去使用
10.6数据索引机制
新华字典:

拼音索引、偏旁部署索引--减少人工查询汉字的时间、减少翻页次数
索引:和数据分开的
保存数据本身的关键信息,而不是全部内容。索引指向数据存放的位置范围
数据结构---树--:二叉树、多叉树、B+Tree
构建了一套更加快速:查询路径
索引操作:
查看表存在的索引:show index from table_name

创建索引:alter table table_name ADD INDEX index_name(key_name)
删除:alter table table_name DROP INDEX index_name; 
10.7数据库集群架构
数据库中间件:shardingsphere
mycat
多个数据库服务器:192.168.1.7:3306
192.168.1.10:3306
每个数据库服务器上,有一张结构一样的表
10.7.1 Shardingspere数据库集群代理
需要依赖java环境,这里我们在创建一个中间件服务器,用来装后续所有的中间件

该服务器的id地址是:192.168.1.2,装有jdk

将文件传到服务器上,并解压

虚拟数据库--本质:数据库代理
server.yaml 配置虚拟数据库用户名和密码
vi server.yaml,内容为
authority:
users:
- user: root
password: zhaoWEILI1314520@
- user: sharding
password: sharding
privilege:
type: ALL_PERMITTED

vi config-sharding.yaml,配置真实数据库的地址,用户名,密码
databaseName: sharding_db
dataSources:
ds_0:
url: jdbc:mysql://192.168.1.7:3306/novel-plus?serverTimezone=UTC&useSSL=false
username: root
password: zhaoWEILI1314520@
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_1:
url: jdbc:mysql://192.168.1.10:3306/novel-plus?serverTimezone=UTC&useSSL=false
username: root
password: zhaoWEILI1314520@
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1

在mysql官网下载mysql驱动包:MySQL :: Download Connector/J

下载那个都可以,这里我下载了第二个,在电脑上解压:将解压后文件里面的
mysql-connector-j-8.0.32.jar包,上传到shardingsphere/lib/目录下
start.bat 或start.sh启动,默认端口:3307
使用时,连接数据库代理,而不是真实的数据库
注意事项:这个软件也是需要单独部署,这个服务器也需要监控起来,这个服务器的配置也需要比较高,所有的sql都需要经过
它不做真实数据存储,只是做SQL的分发和结果的合并
分库分别:一个表拆分为多个表,甚至放在不同的服务器
读写分离:一个数据主服务器,负责写入数据,读取数据的所有sql请求,由其他从服务器进行处理
最后需要配置的:数据库分表策略,测试就不要关注 这么多了,公司不会让测试人员去配置的 。

启动软件:在 bin录下启动:./start.sh,启动后后给出一个目录,,查看:
cat /middleware/ShardingSphere/shardingsphere/logs/stdout.log,出现:
- ShardingSphere-Proxy Standalone mode started successfully,表示 成功

远程连接该虚拟数据库:
mysql -h 192.168.1.2 -P 3307 -uroot -p
-P:指定端口
--uroot:登录用户:root,然后输入密码,即可完成虚拟数据的登录
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象