利用Python实现Excel合并单元格_new_worksheet.merge_cells('a{}:d{}'.format('1','1'-程序员宅基地
利用Python实现Excel合并单元格
最近在工作中需要批量处理一些Excel文件,为了更直观的展示数据,需要对Excel中的单元格进行合并处理。因为一直使用Pandas实现Excel读写操作,而Pandas无法将单元格进行合并,利用Python的xlsxwriter模块可以实现Excel合并单元格。帖子 python之DataFrame写excel合并单元格 中提供了一种方法,但在使用中会出现一些问题,比如无法处理字符串等类型数据。通过修改方法,定义了一个excel_merge_cells函数,基本可以满足日常利用Python实现Excel合并单元格的需求。
原帖方法
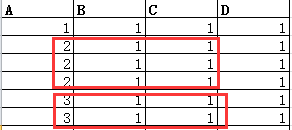
在工作中经常遇到需要将数据输出到excel,且需要对其中一些单元格进行合并,比如如下表表格,需要根据A列的值,合并B、C列的对应单元格
1、定义一个MY_DataFrame类,继承DataFrame类,这样能很好的利用pandas的很多特性,而不用自己重新组织数据结构。
2、定义一个my_mergewr_excel方法,参数分别为:输出excel的路径、用于判断是否需要合并的key_cols列表、用于指明哪些列上的单元格需要被合并的列表
3、将MY_DataFrame封装为一个My_Module模块,以备重用。
合并的算法如下:
1、根据给定参数的【关键列】,进行分组计数和排序,添加CN和RN两个辅助列
2、判断CN大于1的,该分组需要合并,否则该分组(行)无需合并(CN=1说明这个分组数据行是唯一的,无需合并)
3、对应需要合并的分组,判断当前列是不是在给定参数【合并列】中,是则用合并写excel单元格,否则就是普通的写excel单元格。
4、在需要合并的列中,如果对于的RN=1则调用merge_range,一次性写想下写CN个单元格,如果RN>1则跳过该单元格,因为在RN=1的时候,已经合并写了该单元格,若再重复调用erge_range,打开excel文档时会报错。
用图解释如下:

具体代码如下:
# -*- coding: utf-8 -*-
"""
Created on 20170301
@author: ARK-Z
"""
import xlsxwriter
import pandas as pd
class My_DataFrame(pd.DataFrame):
def __init__(self, data=None, index=None, columns=None, dtype=None, copy=False):
pd.DataFrame.__init__(self, data, index, columns, dtype, copy)
def my_mergewr_excel(self,path,key_cols=[],merge_cols=[]):
# sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True):
self_copy=My_DataFrame(self,copy=True)
line_cn=self_copy.index.size
cols=list(self_copy.columns.values)
if all([v in cols for i,v in enumerate(key_cols)])==False: #校验key_cols中各元素 是否都包含与对象的列
print("key_cols is not completely include object's columns")
return False
if all([v in cols for i,v in enumerate(merge_cols)])==False: #校验merge_cols中各元素 是否都包含与对象的列
print("merge_cols is not completely include object's columns")
return False
wb2007 = xlsxwriter.Workbook(path)
worksheet2007 = wb2007.add_worksheet()
format_top = wb2007.add_format({
'border':1,'bold':True,'text_wrap':True})
format_other = wb2007.add_format({
'border':1,'valign':'vcenter'})
for i,value in enumerate(cols): #写表头
#print(value)
worksheet2007.write(0,i,value,format_top)
#merge_cols=['B','A','C']
#key_cols=['A','B']
if key_cols ==[]: #如果key_cols 参数不传值,则无需合并
self_copy['RN']=1
self_copy['CN']=1
else:
self_copy['RN']=self_copy.groupby(key_cols,as_index=False).rank(method='first').ix[:,0] #以key_cols作为是否合并的依据
self_copy['CN']=self_copy.groupby(key_cols,as_index=False).rank(method='max').ix[:,0]
#print(self)
for i in range(line_cn):
if self_copy.ix[i,'CN']>1:
#print('该行有需要合并的单元格')
for j,col in enumerate(cols):
#print(self_copy.ix[i,col])
if col in (merge_cols): #哪些列需要合并
if self_copy.ix[i,'RN']==1: #合并写第一个单元格,下一个第一个将不再写
worksheet2007.merge_range(i+1,j,i+int(self_copy.ix[i,'CN']),j, self_copy.ix[i,col],format_other) ##合并单元格,根据LINE_SET[7]判断需要合并几个
#worksheet2007.write(i+1,j,df.ix[i,col])
else:
pass
#worksheet2007.write(i+1,j,df.ix[i,j])
else:
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
#print(',')
else:
#print('该行无需要合并的单元格')
for j,col in enumerate(cols):
#print(df.ix[i,col])
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
wb2007.close()
self_copy.drop('CN', axis=1)
self_copy.drop('RN', axis=1)
调用代码:
import My_Module
DF=My_DataFrame({
'A':[1,2,2,2,3,3],'B':[1,1,1,1,1,1],'C':[1,1,1,1,1,1],'D':[1,1,1,1,1,1]})
DF
Out[120]:
A B C D
0 1 1 1 1
1 2 1 1 1
2 2 1 1 1
3 2 1 1 1
4 3 1 1 1
5 3 1 1 1
DF.my_mergewr_excel('000_2.xlsx',['A'],['B','C'])
————————————————
版权声明:本文为CSDN博主「周小科」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cakecc2008/article/details/59203980
修改后方法
利用Python进行Excel文件读取并分析多数采用Pandas模块进行,所以直接将方法定义为一个名为 excel_merge_cells 的函数,代码如下:
import pandas as pd
import xlsxwriter
def excel_merge_cells(df, save_name, key_cols=[], merge_cols=[]):
'''key_cols:用于判断是否需要合并的key_cols列表
merge_cols:用于指明哪些列上的单元格需要被合并的列表'''
self_copy = df.copy(deep=True)
line_cn = self_copy.shape[0]
self_copy.index = list(range(line_cn))
cols = list(self_copy.columns)
self_copy['temp_col'] = 1
if all([v in cols for v in key_cols]) == False: # 校验key_cols中各元素 是否都包含与对象的列
raise ValueError("key_cols is not completely include object's columns")
if all([v in cols for v in merge_cols]) == False: # 校验merge_cols中各元素 是否都包含与对象的列
raise ValueError("merge_cols is not completely include object's columns")
wb = xlsxwriter.Workbook(save_name)
worksheet = wb.add_worksheet()
format_top = wb.add_format({
'border':1, 'bold':True, 'text_wrap':True})
format_other = wb.add_format({
'border':1,'valign':'vcenter'})
for i, value in enumerate(cols): # 写表头
worksheet.write(0, i, value, format_top)
if key_cols == []: # 如果key_cols 参数不传值,则无需合并,RN和CN为辅助列
self_copy['CN'] = 1 # 判断CN大于1的,该分组需要合并,否则该分组(行)无需合并(CN=1说明这个分组数据行是唯一的,无需合并)
self_copy['RN'] = 1 # RN为需要合并一组中第几行,CN=1,RN=1;CN=5,RN=1,...5
else:
self_copy['CN'] = self_copy.groupby(key_cols, as_index=False)['temp_col'].rank(method='max')['temp_col'] # method='max',对整个组使用最大排名
self_copy['RN'] = self_copy.groupby(key_cols, as_index=False)['temp_col'].rank(method='first')['temp_col'] # method='first',按照值在数据中出现的次序分配排名
for i in range(line_cn):
if self_copy.loc[i, 'CN'] > 1:
for j, col in enumerate(cols):
if col in (merge_cols):
if self_copy.loc[i, 'RN'] == 1: # 合并写第一个单元格,下一个第一个将不再写
worksheet.merge_range(i+1, j, i+int(self_copy.loc[i, 'CN']), j, self_copy.loc[i, col], format_other)
'''合并 开始行,开始列,结束行,结束列,值,格式'''
'''因为已经写了表头所以从i+1行开始写'''
else:
pass
else:
worksheet.write(i+1, j, self_copy.loc[i, col], format_other)
else:
for j, col in enumerate(cols):
worksheet.write(i+1, j, self_copy.loc[i, col], format_other)
wb.close()
函数需要传入的参数如下:
- df:需要进行合并单元格处理的DataFrame
- save_name:处理结果需要保存的路径及文件名
- key_cols:用于判断是否需要合并的key_cols列表
- merge_cols:用于指明哪些列上的单元格需要被合并的列表
智能推荐
[Mysql] CONVERT函数_mysql convert-程序员宅基地
文章浏览阅读3.1w次,点赞23次,收藏109次。本文主要讲解CONVERT函数_mysql convert
【Android】Retrofit入门详解-程序员宅基地
文章浏览阅读1.6k次,点赞23次,收藏2次。简介:大三学生党一枚!主攻Android开发,对于Web和后端均有了解。个人语录:取乎其上,得乎其中,取乎其中,得乎其下,以顶级态度写好一篇的博客。Retrofit入门一.Retrofit介绍二.Retrofit注解2.1 请求方法注解2.1.1 GET请求2.1.2 POST请求2.2 标记类注解2.2.1 FormUrlEncoded2.2.2 Multipart2.2.3 Streaming2.3 参数类注解2.3.1 Header和Headers2.3.2 Body2.3.3 Path2.3.4_retrofit
教你拷贝所有文件到指定文件夹_所有文件夹下文件的 拷贝怎么弄-程序员宅基地
文章浏览阅读1.9k次。在处理文件的时候,如何将文件、文件夹复制到指定文件夹之中呢?打开【文件批量改名高手】,在“文件批量管理任务”中,先点“添加文件”,将文件素材导入。选好一系列的复制选项,单击开始复制,等全部复制好了,提示“已完成XX%”然后可以任意右击一个文件夹路径,在显示出的下拉列表中,选择“打开文件夹”在“复制到的目标文件夹(目录)”中,导入文件夹,多个文件夹,一行一个。最后,即可看到文件、文件夹都复制到各个指定的文件夹之中一一显示着啦。导入后,在表格中我们就可以看到文件或文件夹的名称以及所排列的序号。..._所有文件夹下文件的 拷贝怎么弄
win10和linux双系统安装步骤(详细!)_怎么装双系统win10和linux-程序员宅基地
文章浏览阅读5k次,点赞11次,收藏42次。Windows10安装ubuntu双系统教程ubuntu分区方案_怎么装双系统win10和linux
从图的邻接表表示转换成邻接矩阵表示_typedef struct arcnode{int adjvex;-程序员宅基地
文章浏览阅读1.1k次。从图的邻接表表示转换成邻接矩阵表示typedef struct ArcNode{ int adjvex;//该弧指向的顶点的位置 struct ArcNode *next;//下一条弧的指针 int weight;//弧的权重} ArcNode;typedef struct{ VertexType data;//顶点信息 ArcNode *firstarc;} VNode,AdList[MAXSIZE];typedef struct{ int vexnum;//顶点数 int _typedef struct arcnode{int adjvex;
学好Python开发你一定会用到这30框架种(1)-程序员宅基地
文章浏览阅读635次,点赞18次,收藏26次。14、fabric是基于Python实现的SSH命令行工具,简化了SSH的应用程序部署及系统管理任务,它提供了系统基础的操作组件,可以实现本地或远程shell命令,包括命令执行,文件上传,下载及完整执行日志输出等功能。7、pycurl 是一个用C语言写的libcurl Python实现,功能强大,支持的协议有:FTP,HTTP,HTTPS,TELNET等,可以理解为Linux下curl命令功能的Python封装。Scipy是Python的科学计算库,对Numpy的功能进行了扩充,同时也有部分功能是重合的。
随便推点
手机能打开的表白代码_能远程打开,各种手机电脑进行监控操作,最新黑科技...-程序员宅基地
文章浏览阅读511次。最近家中的潮人,老妈闲着没事干,开始学玩电脑,引起他的各种好奇心。如看看新闻,上上微信或做做其他的事情。但意料之中的是电脑上会莫名出现各种问题?不翼而飞的图标?照片又不见了?文件被删了,卡机或者黑屏,无声音了,等等问题。常常让她束手无策,求助于我,可惜在电话中说不清,往往只能苦等我回家后才能解决,那种开心乐趣一下子消失了。想想,这样也不是办法啊, 于是,我潜心寻找了两款优秀的远程控制软件。两款软件...
成功Ubuntu18.04 ROS melodic安装Cartograhper+Ceres1.13.0,以及错误总结_ros18.04 安装ca-程序员宅基地
文章浏览阅读1.8k次。二.初始化工作空间三.设置下载地址四.下载功能包此处可能会报错,请看:rosdep update遇到ERROR: error loading sources list: The read operation timed out问题_DD᭄ꦿng的博客-程序员宅基地接下来一次安装所有功能包,注意对应ROS版本 五.编译功能包isolated:单独编译各个功能包,每个功能包之间不产生依赖。编译过程时间比较长,可能需要几分钟时间。此处可能会报错:缺少absl依赖包_ros18.04 安装ca
Harbor2.2.1配置(trivy扫描器、镜像签名)_init error: db error: failed to download vulnerabi-程序员宅基地
文章浏览阅读4.1k次,点赞3次,收藏7次。Haobor2.2.1配置(trivy扫描器、镜像签名)docker-compose下载https://github.com/docker/compose/releases安装cp docker-compose /usr/local/binchmod +x /usr/local/bin/docker-composeharbor下载https://github.com/goharbor/harbor/releases解压tar xf xxx.tgx配置harbor根下建立:mkd_init error: db error: failed to download vulnerability db: database download
openFOAM学习笔记(四)—— openFOAM中的List_openfoam list-程序员宅基地
文章浏览阅读3.2k次。又是一个很底层的部分,但是也非常重要_openfoam list
C++对象的JSON序列化与反序列化探索_c++对象 json 序列化和反序列化 库-程序员宅基地
文章浏览阅读1.7w次,点赞3次,收藏15次。一:背景作为一名C++开发人员,我一直很期待能够像C#与JAVA那样,可以轻松的进行对象的序列化与反序列化,但到目前为止,尚未找到相对完美的解决方案。本文旨在抛砖引玉,期待有更好的解决方案;同时向大家寻求帮助,解决本文中未解决的问题。 二:相关技术介绍本方案采用JsonCpp来做具体的JSON的读入与输出,再结合类成员变量的映射,最终实现对象的JSON序列化与反序列化。本文不再_c++对象 json 序列化和反序列化 库
linux x window 详解,王垠:详解Xwindow(插窗户)的工作原理-程序员宅基地
文章浏览阅读523次。该楼层疑似违规已被系统折叠隐藏此楼查看此楼(本文作者貌似是王垠,在某处扒拉出来的转载过来)Xwindow 是非常巧妙的设计,很多时候它在概念上比其它窗口系统先进,以至于经过很多年它仍然是工作站上的工业标准。许多其它窗口系统的概念都是从 Xwindow 学来的。Xwindow 可以说的东西太多了。下面只分辨一些容易混淆的概念,提出一些正确使用它的建议。分辨 X server 和 X client这..._整个插入的窗叫什么