python网络爬虫实战 pdf是一本由胡松涛所著的python教程工具书,作者以大量实例为基础详细介绍了网络爬虫的编写全过程,非常适合Python网络爬虫初学者以及相关专业师生使用! python网络爬虫实战电子书介绍 ...
”爬虫“ 的搜索结果
python知网爬虫
标签: python爬虫
python知网爬虫,根据作者,爬取所有paper信息
【Python网络爬虫】python爬虫用正则表达式进行数据清洗与处理
全自动爬虫.zip
使用java代码基于MyEclipse开发环境实现爬虫抓取网页中的表格数据,将抓取到的数据在控制台打印出来,需要后续处理的话可以在打印的地方对数据进行操作。包解压后导入MyEclipse就可以使用,在TestCrawTable中右键...
本篇文章主要介绍Python爬虫的由来以及过程,适合刚入门爬虫的同学,文中描述和代码示例很详细,干货满满,感兴趣的小伙伴快来一起学习吧!
然而,随着网站对爬虫的限制和反爬虫技术的不断发展,传统的爬虫方法已经难以满足需求。逆向爬虫技术应运而生,它通过对目标网站的反爬虫机制进行深入分析,并采取相应的对策,从而成功获取数据。
基于网络爬虫技术的网络新闻分析主要用于网络数据爬取。本系统结构如下: (1)网络爬虫模块。 (2)中文分词模块。 (3)中3文相似度判定模块。 (4)数据结构化存储模块。 (5)数据可视化展示模块。

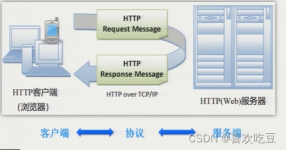
爬虫开发的概要介绍与分析
标签: 爬虫
爬虫开发,作为数据收集和分析的关键技术,涉及自动化地从互联网上抓取和提取信息。以下是对爬虫开发相关资源的描述: 首先,爬虫开发依赖于强大的编程语言和库。Python是爬虫开发中最常用的语言之一,其简洁的语法...
爬虫基础知识点介绍.zip
标签: 爬虫
爬虫,作为互联网数据处理的重要工具,具有广泛的应用场景和复杂的技术原理。以下是对爬虫相关知识点的介绍: 一、爬虫定义与原理 网络爬虫是一种自动化程序,它伪装成客户端与服务器进行数据交互,主要用于数据...
下载地址: Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 D 盘,解压后,将文件夹重新命名为 redis。 打开一个 cmd 窗口 使用 cd 命令切换目录到 C:...
结论: 在本篇博客中,我们介绍了五个实用的Python爬虫案例,并提供了相应的代码示例和解析。这些案例涵盖了不同的应用场景,包括爬取天气数据、图片下载、电影评论、新闻文章爬取和文本分析,以及股票数据爬取和...
Beanbun 是用 PHP 编写的多进程网络爬虫框架,支持分布式,具有良好的开放性、高可扩展性,基于 Workerman,下载可用。
本资源免费开放,爬虫项目,微信公众号文章爬虫,网站文章爬虫,群发邮件系统
通用搜索引擎利用爬虫程序对网站进行检索,如谷歌、百度等面向所有用户的大型搜索引擎,把种子页面作为搜索起点,力图遍历整个网络,尽可能全面搜索到人们 所需的信息。然而,针对某一特定主题,通用搜索引擎存在...
这是一个python专利爬虫,使用中介者模式防止目标网站长时间无响应
源代码步骤说明,操作,流程都有相应的介绍和代码解释,非常清晰明确,拿着就能用,并且可以进一步举一反三,我写的是关于好看视频网站的爬虫,可以将各种视频自动无水印下载,同时通过源代码可以修改URL进行其他...
基于java的网络爬虫项目

一个简单的python示例,实现抓取 嗅事百科 首页内容 ,大家可以自行运行测试
python代码,可以从百度图片获取给定关键词的所有图片网址,并自动命名下载到一个文件夹中
Python爬虫入门教程导航,目标100篇。
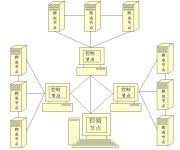
[爬虫]3.2.2 分布式爬虫的架构
标签: 爬虫
在分布式爬虫系统中,通常包括以下几个主要的组成部分:调度器、爬取节点、存储节点。我们接下来将详细介绍每一个部分的功能和设计方法。
增量式更新指的是再更新的时候只更新改变的地方,而为改变的地方则不更新,所以该爬虫。取出待抓取URL,解析DNS得到主机的IP,并将URL对应的网页下载下来,存储进已下载网页库中,并且将这些URL放进已抓取URL队列。...
所以,你知道爬虫的作用了吗?
以上就是爬虫的一些基本知识,主要介绍了网络爬虫的使用工具和反爬虫策略,这些东西在后续对我们的爬虫学习会有所帮助,由于这几年断断续续的写过几个爬虫项目,使用 Java 爬虫也是在前期,后期都是用 Python,最近...
python爬虫100例教程 python爬虫实例100例子 涉及主要知识点: web是如何交互的 requests库的get、post函数的应用 response对象的相关函数,属性 python文件的打开,保存 代码中给出了注释,并且可以直接运行哦...
推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地